I built an AI code reviewer that actually fits into our workflow. It’s a GitLab CI pipeline that reviews merge requests automatically using Claude Code and posts findings as review comments.
I wanted full control over how the reviews work, the ability to tune them for our needs, and a narrow scope of data exposure. Also my job requires a deep understanding of AI instruments and the ways they apply to the products we build, so every project like this sharpens that understanding. There are existing tools out there, but I wanted to understand the problem first by getting my hands dirty.
Here’s what I ended up with: a central CI pipeline that any project can opt into by adding a small trigger job to their CI config. When a developer opens or updates a merge request, the pipeline kicks off. Claude clones the branch, reads the diff, fetches the Jira ticket referenced in the description or commit messages, queries our internal platform documentation, reads the full discussion history on the merge request, and posts a single review comment with findings.
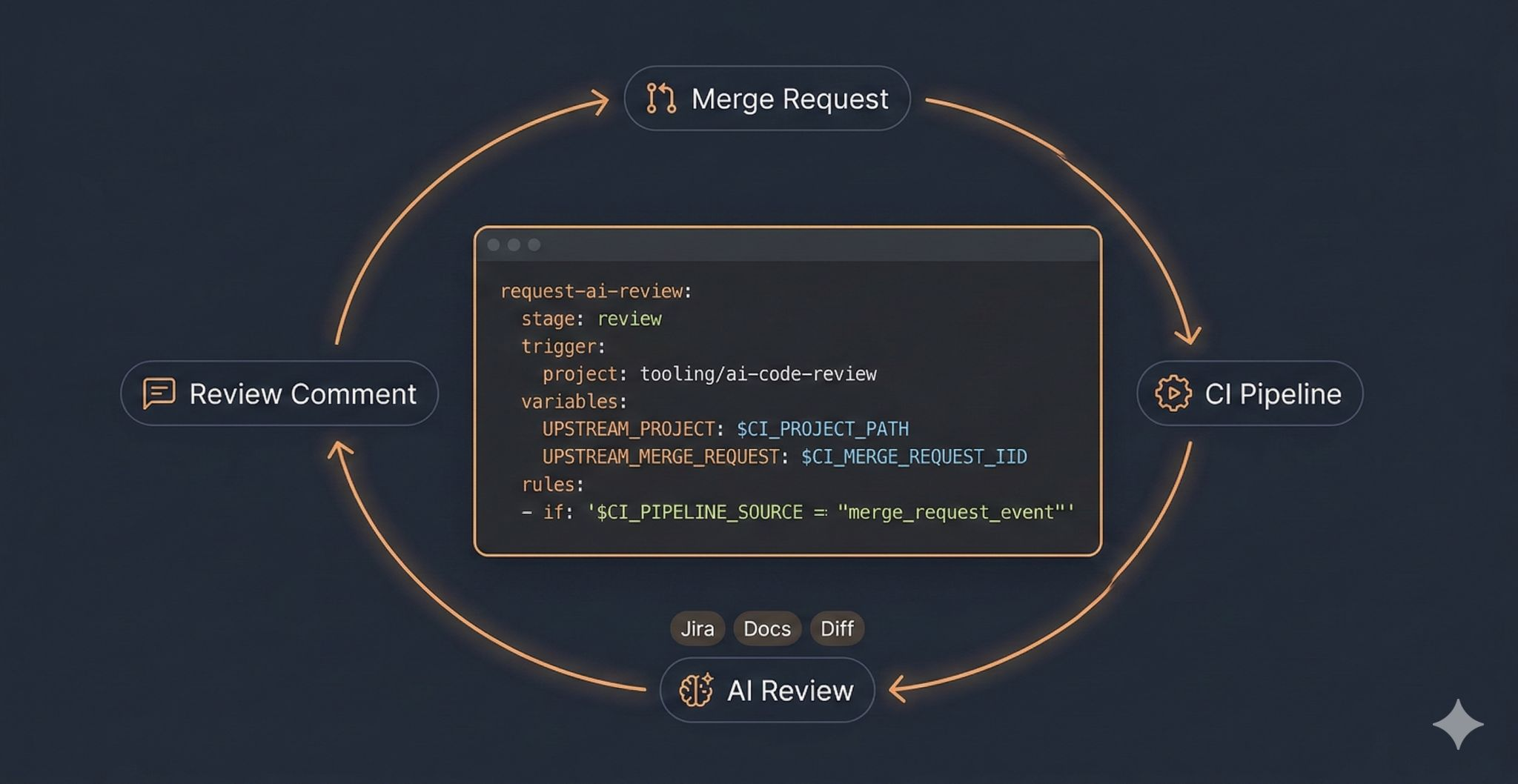
It goes further than “review this diff.” The reviewer checks changes against the Jira ticket’s acceptance criteria. It reads project conventions. It knows what was already flagged in previous reviews and doesn’t repeat itself. And it deliberately focuses on things that matter: bugs, security issues, data-loss risks, design flaws. Stylistic or subjective notes are omitted by design.
One thing I want to be clear about: this does not replace human code review. It also doesn’t replace the developer’s own review before submitting. We expect developers to produce the best work they can before opening a merge request. This is an additional safety net. A centralised guard that catches things people miss under time pressure, and a way to enforce practices across all projects without relying on one person remembering everything.
Building this was more about prompt engineering than infrastructure. The prompt that tells the AI what to review, how to prioritise, and how to format its output, that’s where most of my time went. I went through many iterations, and small wording changes had outsized effects on quality.
The other lesson was about efficiency. The agent can do a lot: clone repos, call APIs, parse responses. But it doesn’t mean it should. When I extracted deterministic steps like checking out the branch or fetching MR comments into shell scripts, the agent stopped spending tokens figuring out how to do those things and focused on what it’s actually good at: reading code and making judgments. Faster and more predictable.
It’s still an experiment. It catches real issues: missing acceptance criteria, potential UX problems, bugs that are easy to miss in a large diff. It also adds noise sometimes, and tuning that balance is most of the ongoing work. But after many rounds of testing with our team, it’s become a tool we actually use.
This article was originally published on LinkedIn on 2026-03-05.